KOCA性能问题自检手册
针对KOCA体系下的开发,可能遇到的一些常见的性能相关问题的排查和解决方案。
一、常见性能开发问题
1. 参数解析
1.1 占位符解析
问题描述
在多数据源切换场景中,environment.resolvePlaceholders(value) 用于解析配置文件中的占位符(如: ${db.master}),该方法内部需遍历 PropertySources,解析嵌套占位符(如 ${db.${env}.url}),存在计算开销。如果频繁调用此方法,尤其是在高并发场景下,重复解析相同的占位符字符串会带来不必要的性能损耗。建议缓存占位符解析结果,后续直接从缓存读取,能够显著提高性能。
错误实现
代码每次调用时,都要解析一次占位符:
public class OriginalDataSourceResolver {
private Environment environment;
public String resolve(String dataSourceId) {
// 每次调用都解析占位符
return environment.resolvePlaceholders(dataSourceId);
}
}
正确实现
通过 ConcurrentHashMap 缓存解析结果,避免重复解析:
public class OptimizedDataSourceResolver {
private Environment environment;
private final Map<String, String> cache = new ConcurrentHashMap<>();
public String resolve(String dataSourceId) {
// 使用缓存避免重复解析
return cache.computeIfAbsent(dataSourceId, environment::resolvePlaceholders);
}
}
性能对比测试
-
性能测试验证:JMH基准测试
-
测试目标:对比无缓存与有缓存的解析性能
-
测试数据:
简单占位符:
${db.master}
复杂占位符:${db.${env}.url} -
并发量:模拟 16 个线程并发调用
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(value = 4)
@Warmup(iterations = 5, time = 5)
@Measurement(iterations = 5, time = 10)
@Threads(16)
public class PlaceholderResolveBenchmark {
private OriginalDataSourceResolver originalResolver;
private OptimizedDataSourceResolver optimizedResolver;
private final String simplePlaceholder = "${db.master}";
private final String complexPlaceholder = "${db.${env}.url}";
@Setup(Level.Trial)
public void setup() {
MockEnvironment env = new MockEnvironment();
env.setProperty("db.master", "masterDataSource");
env.setProperty("env", "prod");
env.setProperty("db.prod.url", "jdbc:mysql://localhost:3306/db");
originalResolver = new OriginalDataSourceResolver();
originalResolver.setEnvironment(env);
optimizedResolver = new OptimizedDataSourceResolver();
optimizedResolver.setEnvironment(env);
}
/**
* 测试原始解析器-简单占位符
* @param bh
*/
@Benchmark
public void testOriginalResolver_Simple(Blackhole bh) {
String result = originalResolver.resolve(simplePlaceholder);
bh.consume(result);
}
/**
* 测试优化解析器-简单占位符
* @param bh
*/
@Benchmark
public void testOptimizedResolver_Simple(Blackhole bh) {
String result = optimizedResolver.resolve(simplePlaceholder);
bh.consume(result);
}
/**
* 测试原始解析器-复杂占位符
* @param bh
*/
@Benchmark
public void testOriginalResolver_Complex(Blackhole bh) {
String result = originalResolver.resolve(complexPlaceholder);
bh.consume(result);
}
/**
* 测试优化解析器-复杂占位符
* @param bh
*/
@Benchmark
public void testOptimizedResolver_Complex(Blackhole bh) {
String result = optimizedResolver.resolve(complexPlaceholder);
bh.consume(result);
}
}
测试结果:
Benchmark Mode Cnt Score Error Units
TT.PlaceholderResolveBenchmark.testOptimizedResolver_Complex thrpt 20 315340.801 ± 59664.044 ops/ms
TT.PlaceholderResolveBenchmark.testOptimizedResolver_Simple thrpt 20 332918.070 ± 51588.217 ops/ms
TT.PlaceholderResolveBenchmark.testOriginalResolver_Complex thrpt 20 18.058 ± 2.609 ops/ms
TT.PlaceholderResolveBenchmark.testOriginalResolver_Simple thrpt 20 36.011 ± 3.894 ops/ms
测试结论:
优化后的 OptimizedDataSourceResolver 性能提升显著,吞吐量达到原始方案的 1万倍,缓存策略对高频占位符解析场景有非常明显的优化效果。
1.2 Environment.getProperty()
问题描述
在 HTTP 过滤器、拦截器等高频调用场景中,直接使用 environment.getProperty("key") 获取配置属性会带来性能损耗,因为每次调用都需遍历 PropertySources 查找键值。建议缓存获取配置属性结果,后续请求直接从缓存中获取配置属性,能够提高性能。
相关场景
- HTTP 过滤器/拦截器:每个请求均触发
getProperty - 循环体内部:避免在循环中重复调用
getProperty - 需要频繁读取固定配置的场景(如服务名、版本号、开关配置)
错误实现
每次请求多次触发 getProperty 调用,存在严重性能损耗:
public class KocaHttpResponseFilter extends OncePerRequestFilter {
@Autowired
private Environment environment;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
// 每次请求调用 getProperty,存在性能隐患
setHeader(response, "X-App-Name", environment.getProperty("spring.application.name"));
setHeader(response, "X-App-Version", environment.getProperty("koca.monitor.application.version"));
filterChain.doFilter(request, response);
}
private void setHeader(HttpServletResponse response, String key, String value) {
if (StringUtils.hasText(value)) {
response.setHeader(key, value);
}
}
}
正确实现
缓存配置值,在初始化阶段一次性读取配置,避免重复调用 getProperty:
public class KocaHttpResponseFilter extends OncePerRequestFilter {
private String appName;
private String appVersion;
@Autowired
private Environment environment;
@Override
protected void initFilterBean() {
// 初始化阶段一次性读取配置
this.appName = environment.getProperty("spring.application.name");
this.appVersion = environment.getProperty("koca.monitor.application.version");
}
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
// 直接使用缓存值
setHeader(response, "X-App-Name", appName);
setHeader(response, "X-App-Version", appVersion);
filterChain.doFilter(request, response);
}
private void setHeader(HttpServletResponse response, String key, String value) {
if (StringUtils.hasText(value)) {
response.setHeader(key, value);
}
}
}
性能对比测试
- 性能测试验证:JMH 基准测试
- 测试目标:对比无缓存与有缓存的解析性能
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(2)
@Warmup(iterations = 3, time = 2)
@Measurement(iterations = 5, time = 5)
@Threads(8) // 模拟 8 线程并发
public class EnvironmentGetPropertyBenchmark {
private Environment environment;
private String appName;
private String appVersion;
@Setup
public void setup() {
// 初始化 MockEnvironment
MockEnvironment env = new MockEnvironment();
env.setProperty("spring.application.name", "my-service");
env.setProperty("koca.monitor.application.version", "1.0.0");
this.environment = env;
// 优化版本预读取配置
this.appName = env.getProperty("spring.application.name");
this.appVersion = env.getProperty("koca.monitor.application.version");
}
/** 原始实现:每次调用 getProperty */
@Benchmark
public void testOriginal(Blackhole bh) {
bh.consume(environment.getProperty("spring.application.name"));
bh.consume(environment.getProperty("koca.monitor.application.version"));
}
/** 优化实现:使用缓存值 */
@Benchmark
public void testOptimized(Blackhole bh) {
bh.consume(appName);
bh.consume(appVersion);
}
}
测试结果:
Benchmark Mode Cnt Score Error Units
TT.EnvironmentGetPropertyBenchmark.testOptimized thrpt 10 1335706.702 ± 100309.134 ops/ms
TT.EnvironmentGetPropertyBenchmark.testOriginal thrpt 10 20.171 ± 0.972 ops/ms
测试结论:
优化后性能提升显著,性能较原始方案提升了6万多倍,缓存策略对高频调用environment.getProperty() 场景有非常明显的优化效果。
2. 日志打印
2.1 善用 isDebugEnabled()
问题描述
在高频日志调用场景中,直接使用 log.debug输出日志时,即使日志级别高于 debug,也会频繁执行日志输出内容里的方法调用,如: JsonUtils.toJson(),导致不必要的性能损耗。建议在日志输出前,使用isDebugEnabled()判断当前是否debug日志级别,再进行日志输出。
错误实现
在没有开启 debug 级别的时候,也会执行 JsonUtils.toJson方法:
// 1:无条件直接调用
LOGGER.debug("调用功能号:{},返回参数:{}", pathApiCode, JsonUtils.toJson(serviceResponse));
正确实现
使用isDebugEnabled()判断当前是否debug日志级别,若非debug级别则不会执行 JsonUtils.toJson方法:
// 2:有条件检查
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("ans: api={} ans body:{}", pathApiCode, JsonUtils.toJson(serviceResponse));
}
2.2 慎用 LogUtils
问题描述
在koca-common-tools 工具包中,LogUtils 提供了统一的日志记录接口,虽然使用起来更加方便,但其内部实现存在一定性能损耗,并不适用于在高并发或高频调用的业务场景(如网关、实时计算、交易核心等)中使用。建议在对性能敏感的链路上编写代码时,使用 Logger logger = LoggerFactory.getLogger(xxx.class); 这种slf4j原生的方式记录日志。
错误实现
使用 LogUtils在高并发或高频调用的业务场景下进行日志打印:
LogUtils.debug("命中缓存{}", cacheName);
正确实现
换成使用slf4j原生的方式打印日志:
private static final Logger LOGGER = LoggerFactory.getLogger(ZkLeaderSelector.class);
LOGGER.debug("命中缓存{}", cacheName);
性能对比测试
- 性能测试验证:JMH基准测试
- 测试目标:对比 LogUtils 和 slf4j 中的 LOGGER 性能
@BenchmarkMode({Mode.Throughput})
@Warmup(iterations = 5, time = 2)
@Measurement(iterations = 10, time = 3)
@Fork(value = 3)
@Threads(4)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class LogUtilsPerfBenchMark {
private static final Logger LOGGER = LoggerFactory.getLogger(LogUtilsPerfBenchMark.class);
@Benchmark
public void testLogByLoggerFactory() {
LOGGER.info("test");
}
@Benchmark
public void testLogByLogUtils() {
LogUtils.info("test");
}
}
测试结果:
Benchmark Mode Cnt Score Error Units
LogUtilsPerfBenchMark.testLogByLogUtils thrpt 30 32.329 ± 6.478 ops/ms
LogUtilsPerfBenchMark.testLogByLoggerFactory thrpt 30 35.570 ± 4.939 ops/ms
测试结论:
在相同的测试条件下,使用 LoggerFactory 记录日志的效率要比使用 LogUtils 的性能大约提升了 10%。
3. 反射
3.1 优化反射获取真实目标对象
问题描述
在多租户数据隔离插件 SqlParserInterceptor 中,realTarget 方法用于递归获取被代理对象的真实目标对象。但在高并发场景下,频繁的反射操作(Proxy.isProxyClass 和 MetaObject.getValue 每次调用均需检查代理类并反射获取字段)会导致性能下降。建议直接引用目标对象,必要时通过缓存减少反射开销。
错误实现
StatementHandler statementHandler = realTarget(invocation.getTarget());
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
private static <T> T realTarget(Object target) {
if (Proxy.isProxyClass(target.getClass())) {
MetaObject metaObject = SystemMetaObject.forObject(target);
return realTarget(metaObject.getValue("h.target"));
}
return (T) target;
}
正确实现
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
性能对比测试
性能测试验证:JMH基准测试
/**
* 比较使用 realTarget 方法拆解代理与直接使用代理对象的性能差异
*/
public class RealTargetBenchmark {
/**
* 模拟 StatementHandler 接口
*/
public interface StatementHandler {
void handle();
}
/**
* Mock 实现
*/
public static class MockStatementHandler implements StatementHandler {
@Override
public void handle() {
}
}
/**
* 自定义 InvocationHandler,保存真实目标对象
*/
public static class TargetInvocationHandler implements InvocationHandler {
private final Object target;
public TargetInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return method.invoke(target, args);
}
}
/**
* 初始化
*/
@State(Scope.Thread)
public static class BenchmarkState {
StatementHandler proxyHandler;
StatementHandler realHandler;
@Setup(Level.Trial)
public void setup() {
// 原始目标对象
realHandler = new MockStatementHandler();
// 使用自定义 InvocationHandler 生成代理对象,保证内部有 target 字段
proxyHandler = (StatementHandler) Proxy.newProxyInstance(StatementHandler.class.getClassLoader(),
new Class[]{StatementHandler.class}, new TargetInvocationHandler(realHandler));
}
}
/**
* 修改后的 realTarget 方法,使用 Proxy.getInvocationHandler 获取 InvocationHandler
*/
@SuppressWarnings("unchecked")
private static <T> T realTarget(Object target) {
if (Proxy.isProxyClass(target.getClass())) {
// 使用标准 API 获取 InvocationHandler
InvocationHandler handler = Proxy.getInvocationHandler(target);
try {
// 反射获取 handler 内部的 "target" 字段
Field targetField = handler.getClass().getDeclaredField("target");
targetField.setAccessible(true);
Object innerTarget = targetField.get(handler);
return realTarget(innerTarget);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException("Failed to retrieve target from proxy invocation handler", e);
}
}
return (T) target;
}
/**
* 调用 realTarget 方法
*/
@Benchmark
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public Object testWithRealTarget(BenchmarkState state, Blackhole bh) {
Object target = realTarget(state.proxyHandler);
bh.consume(target);
return target;
}
/**
* 直接返回代理对象
*/
@Benchmark
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public Object testWithoutRealTarget(BenchmarkState state, Blackhole bh) {
Object target = state.proxyHandler;
bh.consume(target);
return target;
}
}
测试结果:
Benchmark Mode Cnt Score Error Units
TT.RealTargetBenchmark.testWithRealTarget thrpt 25 16488.266 ± 1702.619 ops/ms
TT.RealTargetBenchmark.testWithoutRealTarget thrpt 25 285215.686 ± 68243.335 ops/ms
测试结论:
testWithoutRealTarget 比 testWithRealTarget 的性能大约提升了 1630%。
4. sql优化
4.1 where 1=1
问题描述
在动态 SQL 拼接场景中,开发者常使用 WHERE 1=1 简化条件拼接逻辑(避免处理首个条件的 AND)。理论上,数据库优化器会忽略 1=1,但字符串拼接可能带来性能损耗,部分数据库优化器可能无法完全优化 1=1,导致索引失效或全表扫描。建议使用<where> 标签替代 WHERE 1=1 。
错误实现
select *
from koca_job_info
where 1=1
<if test="jobName != null and jobName != '' ">
<bind name="jobNameBind" value="'%' + jobName + '%'"/>
and job_name like #{jobNameBind}
</if>
正确实现
select *
from koca_job_info
<where>
<if test="jobName != null and jobName != '' ">
<bind name="jobNameBind" value="'%' + jobName + '%'"/>
job_name like #{jobNameBind}
</if>
性能对比测试
-
数据库:mysql-8.0.29
-
EXPLAIN测试对比:
EXPLAIN SELECT * FROM koca_order WHERE 1=1 AND order_id > 1012
EXPLAIN SELECT * FROM koca_order WHERE order_id > 1012
| id | select_type | type | possible_keys | rows | filtered | Extra |
|---|---|---|---|---|---|---|
| 1 | SIMPLE | ALL | PRIMARY | 600 | 33.33 | Using where |
- JMH测试:
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Benchmark)
@Fork(3)
@Warmup(iterations = 5, time = 2)
@Measurement(iterations = 5, time = 5)
@Threads(16)
public class WhereConditionBenchmark {
private List<String> conditions;
@Setup
public void setup() {
// 模拟 5 个动态查询条件
conditions = Arrays.asList("age > 18", "status = 1", "name LIKE 'John%'", "city = 'NY'", "score >= 60");
}
/**
* 原始实现:使用 WHERE 1=1 简化拼接
*/
@Benchmark
public void withDummyCondition(Blackhole bh) {
StringBuilder sql = new StringBuilder("SELECT * FROM users WHERE 1=1");
for (String cond : conditions) {
sql.append(" AND ").append(cond);
}
bh.consume(sql.toString()); // 避免 JIT 优化
}
/**
* 优化实现:直接拼接 WHERE 条件
*/
@Benchmark
public void withoutDummyCondition(Blackhole bh) {
StringBuilder sql = new StringBuilder("SELECT * FROM users");
boolean first = true;
for (String cond : conditions) {
if (first) {
sql.append(" WHERE ");
first = false;
} else {
sql.append(" AND ");
}
sql.append(cond);
}
bh.consume(sql.toString());
}
}
测试结果:
Benchmark Mode Cnt Score Error Units
TT.WhereConditionBenchmark.withDummyCondition thrpt 15 16509.986 ± 3028.386 ops/ms
TT.WhereConditionBenchmark.withoutDummyCondition thrpt 15 20124.583 ± 420.773 ops/ms
测试结论:
移除冗余的 WHERE 1=1 后,吞吐量提升约 21.9%,说明 1=1 对动态 SQL 生成性能有明显影响。
4.2 EXISTS 替代 IN 子查询
问题描述
在复杂查询中,有时需要使用 IN 子查询判断记录是否存在。但当子查询结果集较大时,IN 会导致性能问题:数据库需先执行子查询生成完整结果集,再进行主查询匹配。而 EXISTS 在子查询找到第一条匹配记录时即返回,可显著减少计算量。建议合理使用 EXISTS 替代 IN 子查询。
错误实现
-- 原始 SQL(使用 IN)
SELECT *
FROM orders o
WHERE o.customer_id IN (
SELECT c.id
FROM customers c
WHERE c.country = 'US'
);
正确实现
-- 优化后 SQL(使用 EXISTS)
SELECT *
FROM orders o
WHERE EXISTS (
SELECT 1
FROM customers c
WHERE c.id = o.customer_id
AND c.country = 'US'
);
性能对比测试
-- 原始 SQL 执行计划(IN)
EXPLAIN SELECT * FROM orders WHERE customer_id IN (SELECT id FROM customers WHERE country='US');
-- 优化后 SQL 执行计划(EXISTS)
EXPLAIN SELECT * FROM orders o WHERE EXISTS (SELECT 1 FROM customers c WHERE c.id=o.customer_id AND c.country='US');
| 优化类型 | type | key | rows | Extra |
|---|---|---|---|---|
| 原始(IN) | ALL | NULL | 10,000 | Using where |
| 优化(EXISTS) | eq_ref | PRIMARY | 1 | Using index |
测试结论:
-
IN导致主查询全表扫描(type=ALL),未利用索引。 -
EXISTS通过关联索引(PRIMARY)实现高效匹配,扫描行数从 10,000 降为 1。
优化建议
- 优先使用 EXISTS:
在判断记录存在性时,EXISTS比IN更高效,尤其子查询关联主表字段时 - 索引配合:
确保子查询关联字段(如c.id=o.customer_id)有索引,否则EXISTS可能退化为全表扫描 - 避免滥用 NOT IN:
NOT EXISTS同理优于NOT IN,但需注意NULL值处理(NOT IN隐含NULL逻辑陷阱) - 结合业务场景:
若子查询结果集极小(如 <100 条),IN可能更直观且性能相当,但需通过执行计划验证
5. 线程池优化
5.1 怎么调整线程大小最合适?
问题描述
核心线程数、最大线程数是不是越大越好?
线程池的核心线程数(corePoolSize)和最大线程数(maximumPoolSize)的设定需根据任务类型和系统资源动态调整,盲目调大可能引发性能问题甚至系统崩溃。建议根据CPU核数以及实际业务需要进行配置。
1. CPU密集型任务:线程数过多会引发频繁的上下文切换,消耗CPU资源。
2. IO密集型任务:线程数过大可能导致内存耗尽(每个线程占用栈内存)或触发拒绝策略。
性能对比测试
- 性能测试验证:JMH基准测试
- 测试目标:对比不同线程池配置的效果,配置的是否合理
案例1:CPU密集型任务(计算素数)
public class CpuIntensiveDemo {
private static final AtomicInteger counter = new AtomicInteger(0);
/**
* 固定任务数
*/
private static final int TASK_COUNT = 100000;
// 计算第5个素数
private static int calculatePrime(int n) {
int count = 0, num = 2;
while (count < n) {
boolean isPrime = true;
for (int i = 2; i <= Math.sqrt(num); i++) {
if (num % i == 0) {
isPrime = false;
break;
}
}
if (isPrime) {
count++;
}
num++;
}
// 记录完成的任务数
counter.incrementAndGet();
return num - 1;
}
public static void main(String[] args) {
int logicalProcessors = Runtime.getRuntime().availableProcessors();
// 合理配置:线程数 = 逻辑处理器数(16)
ThreadPoolExecutor executor1 = new ThreadPoolExecutor(logicalProcessors, logicalProcessors, 1, TimeUnit.SECONDS,
new LinkedBlockingQueue<>());
// 错误配置:线程数 = 160(远超过逻辑处理器数)
ThreadPoolExecutor executor2 =
new ThreadPoolExecutor(160, 160, 1, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
Runnable task = () -> calculatePrime(5);
runTest("合理配置(16线程)", executor1, task, TASK_COUNT);
runTest("错误配置(160线程)", executor2, task, TASK_COUNT);
}
private static void runTest(String name, ThreadPoolExecutor executor, Runnable task, int taskCount) {
counter.set(0);
long start = System.currentTimeMillis();
for (int i = 0; i < taskCount; i++) {
executor.execute(task);
}
// 停止接受新任务
executor.shutdown();
try {
// 等待所有任务完成
executor.awaitTermination(1, TimeUnit.MINUTES);
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.printf("%s 总耗时:%d ms (完成数: %d)\n", name, end - start, counter.get());
}
}
运行结果:
合理配置(16线程) 总耗时:50 ms (完成数: 100000)
错误配置(160线程) 总耗时:85 ms (完成数: 100000)
测试结论:
线程数并非越大越好,当线程数超过硬件并行能力时,调度开销会显著降低性能。
案例2: IO密集型任务(模拟网络请求)
public class IoIntensiveDemo {
// 模拟IO密集型任务:模拟网络请求(睡眠代替IO等待)
private static void mockHttpRequest() {
try {
Thread.sleep(100); // 模拟IO等待100ms
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// 场景1:线程数过小(错误配置)
ThreadPoolExecutor executor1 = new ThreadPoolExecutor(2, 2, 1, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
// 场景2:合理放大线程数(正确配置)
int logicalProcessors = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor executor2 = new ThreadPoolExecutor(logicalProcessors, logicalProcessors * 2, 1, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
// 提交任务并统计执行时间
Runnable task = () -> mockHttpRequest();
runTest("错误配置(2线程)", executor1, task);
runTest("合理配置(" + logicalProcessors + "线程)", executor2, task);
}
private static void runTest(String name, Executor executor, Runnable task) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
executor.execute(task);
}
((ThreadPoolExecutor) executor).shutdown();
while (!((ThreadPoolExecutor) executor).isTerminated()) {
}
long end = System.currentTimeMillis();
System.out.printf("%s 总耗时:%d ms\n", name, end - start);
}
}
运行结果:
错误配置(2线程) 总耗时:5522 ms
合理配置(16线程) 总耗时:763 ms
测试结论:
IO密集型任务中,适当增大线程数可显著提升吞吐量。
5.2 资源泄漏(线程未关闭)
问题描述
应用程序启动时创建线程池处理任务,但未在应用关闭时正确关闭线程池,残留的线程池线程仍在运行,占用内存和CPU资源。此外,若线程池任务涉及外部资源(如数据库连接),可能导致资源耗尽或端口占用。一定要注意正确关闭线程池。
错误实现
未正确关闭线程池:
public class ResourceLeakDemo {
private static final ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>()
);
public static void main(String[] args) {
executor.execute(() -> {
while (true) {
try {
System.out.println("执行任务中...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 模拟应用关闭(未关闭线程池)
System.out.println("主线程结束,但线程池仍在运行!");
}
}
运行结果
主线程结束,但线程池仍在运行!
执行任务中...
执行任务中...
...
主线程结束后,线程池中的核心线程(非守护线程)会持续运行,导致JVM无法退出。
正确实现
正确关闭线程池:
public class ResourceLeakFixedDemo {
private static final ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>()
);
public static void main(String[] args) {
// 注册JVM关闭钩子
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
System.out.println("JVM关闭钩子触发:关闭线程池...");
shutdownThreadPool();
}));
executor.execute(() -> {
while (true) {
try {
System.out.println("执行任务中...");
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("任务被中断,退出循环");
break;
}
}
});
// 模拟正常关闭(手动调用关闭逻辑)
shutdownThreadPool();
System.out.println("应用主线程结束");
}
private static void shutdownThreadPool() {
executor.shutdown(); // 停止接受新任务,等待已有任务完成
try {
// 等待任务终止,最多10秒
if (!executor.awaitTermination(10, TimeUnit.SECONDS)) {
executor.shutdownNow(); // 强制终止所有任务
System.out.println("线程池强制关闭");
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
}
}
运行结果:
执行任务中...
执行任务中...
JVM关闭钩子触发:关闭线程池...
执行任务中...
执行任务中...
执行任务中...
执行任务中...
线程池强制关闭
应用主线程结束
任务被中断,退出循环
解决方案
- **显式调用 **
shutdown()、shutdownNow():在应用退出逻辑中手动关闭线程池。
public void shutdownGracefully(long waitTimeMillis) {
// 停止接受新任务
shutdown();
try {
if (!isTerminated()) {
// 等待已有任务执行完成
boolean ret = awaitTermination(waitTimeMillis, TimeUnit.MILLISECONDS);
if (!ret) {
// 尝试立即停止所有正在执行的任务
shutdownNow();
logger.warn("等待{}s超时,直接关闭线程池{}", waitTimeout, this.name);
}
}
} catch (InterruptedException e) {
logger.warn("关闭线程池{}被中断", name, e);
}
}
- 注册JVM关闭钩子:确保即使非正常退出(如kill命令),也能触发线程池关闭。
Runtime.getRuntime().addShutdownHook(new Thread(() -> shutdownThreadPool()));
注意:注册JVM钩子关闭线程池的方式,对于非守护线程类型的ScheduledThreadPool要慎用,可能会导致钩子函数失效(因为该钩子是在JVM退出时触发的,而仅当所有非守护线程都退出时、JVM才会退出,而定时任务会导致非守护线程无法被回收)。
5.3 任务堆积导致 OOM(内存溢出)
问题描述
使用无界队列(如 LinkedBlockingQueue)的线程池,在任务提交速率远高于处理速率时,队列无限堆积,最终导致内存溢出(OOM)。
错误实现
public class QueueOOMDemo {
// 静态集合防止GC回收内存(加速OOM)
private static final List<byte[]> memoryHolder = new ArrayList<>();
public static void main(String[] args) {
// 使用无界队列(快速堆积大对象)
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>());
// 提交大量任务,每个任务分配2MB内存(加速内存消耗)
for (int i = 0; i < 20000; i++) {
executor.execute(() -> {
// 分配2MB内存,并存入静态集合防止GC回收
byte[] chunk = new byte[2 * 1024 * 1024];
synchronized (memoryHolder) {
memoryHolder.add(chunk);
}
// 模拟任务耗时
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}
运行结果
Exception in thread "pool-1-thread-2" Exception in thread "pool-1-thread-3" Exception in thread "pool-1-thread-1" Exception in thread "pool-1-thread-4" Exception in thread "pool-1-thread-6" Exception in thread "pool-1-thread-5" Exception in thread "pool-1-thread-7" Exception in thread "pool-1-thread-8" java.lang.OutOfMemoryError: Java heap space
at com.szkingdom.example.thread01.QueueOOMDemo.lambda$main$0(QueueOOMDemo.java:30)
at com.szkingdom.example.thread01.QueueOOMDemo$$Lambda$1/897913732.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "pool-1-thread-12" java.lang.OutOfMemoryError: Java heap space
Exception in thread "pool-1-thread-13" java.lang.OutOfMemoryError: Java heap space
问题分析
- 无界队列风险:默认队列容量为 `Integer.MAX_VALUE`,任务无限堆积,直至内存耗尽。
- OOM类型:通常为 `GC overhead limit exceeded` 或 `Java heap space`。
正确实现
- 限制队列容量:使用有界队列,防止任务无限堆积。
- 合理拒绝策略:任务满时触发拒绝策略,避免内存溢出。
public class QueueOOMFixedDemo {
public static void main(String[] args) {
// 使用有界队列(容量1000)和拒绝策略
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, 4, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1000), // 队列容量1000
new ThreadPoolExecutor.AbortPolicy()
);
try {
for (int i = 0; i < 20000; i++) {
executor.execute(() -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
} catch (RejectedExecutionException e) {
System.err.println("任务被拒绝,已提交任务数:" + executor.getTaskCount());
}
executor.shutdown();
}
}
运行结果
任务被拒绝,已提交任务数:1004
5.4 死锁(任务互相等待)
问题描述
任务向同一线程池提交子任务并等待其完成,导致线程池资源耗尽,形成死锁。
错误实现
- 线程池饱和:父任务占用唯一线程,子任务进入队列等待。
- 互相等待:父任务等待子任务完成,子任务因队列满无法执行。
public class DeadlockDemo {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1, 1, 0, TimeUnit.SECONDS,
new LinkedBlockingQueue<>()
);
// 提交父任务
executor.execute(() -> {
System.out.println("父任务开始");
Future<?> future = executor.submit(() -> {
System.out.println("子任务开始");
return "子任务结果";
});
try {
future.get(); // 等待子任务完成(但线程池已满,子任务无法执行)
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("父任务结束");
});
}
}
运行结果
父任务开始
(程序挂起,无后续输出)
正确实现
- 解耦任务依赖:避免同一线程池内任务相互等待。
- 使用独立线程池:父子任务由不同线程池处理。
public class DeadlockFixedDemo {
public static void main(String[] args) {
ThreadPoolExecutor parentExecutor =
new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
ThreadPoolExecutor childExecutor =
new ThreadPoolExecutor(2, 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
// 提交父任务并获取Future
Future<?> parentFuture = parentExecutor.submit(() -> {
System.out.println("父任务开始");
Future<?> childFuture = childExecutor.submit(() -> {
System.out.println("子任务开始");
return "子任务结果";
});
try {
childFuture.get(); // 等待子任务完成
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("父任务结束");
});
try {
// 等待父任务完成
parentFuture.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
// 父任务完成后关闭线程池
parentExecutor.shutdown();
childExecutor.shutdown();
}
}
}
运行结果
父任务开始
子任务开始
父任务结束
二、性能问题排查
在大多数业务场景中,都会遇到一些性能瓶颈,进而需要性能调优,而对工具的选型是比较重要的一环,下面介绍下常用的性能调优工具。从吞吐量、时延、内存占用、GC耗时等多种指标介绍对应性能调优的工具。
排查工具介绍
JVM工具
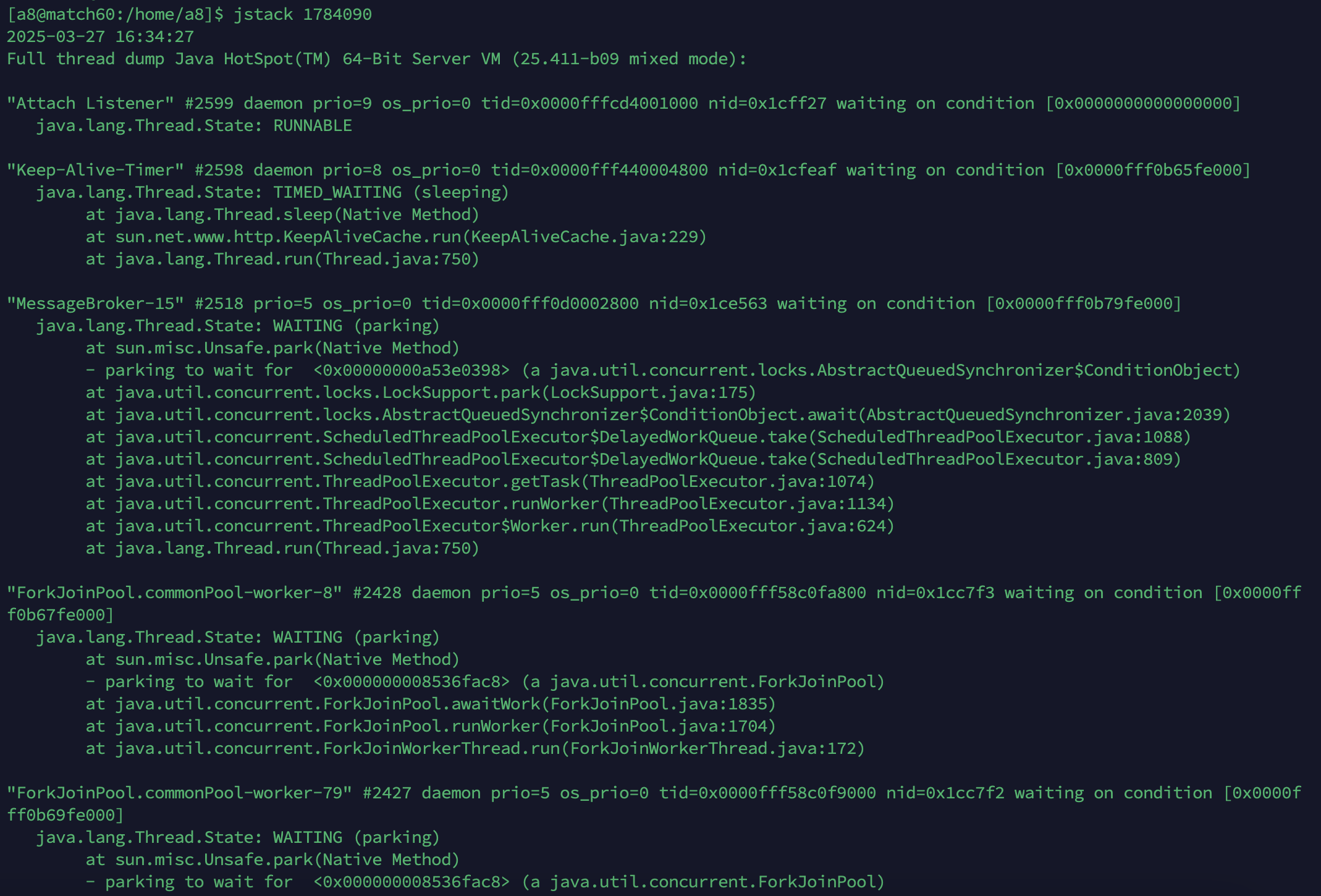
jstack
jstack 命令可以生成 JVM 当前时刻的线程快照,包括线程的调用栈、状态等,常用于分析线程状态、排查死锁、线程阻塞、CPU 占用高等问题。
基本命令如下:
jstack 进程ID
输出如下:
jstat
jstat 命令允许以固定的监控频次输出 JVM 的资源使用情况,常用于分析垃圾回收情况、排查内存泄漏等问题。
基本命令如下:
jstat -gcutil -h10 <PID> 1000 # 每1秒输出一次GC统计,每10行显示表头
输出如下:
➜ ~ jstat -gcutil 23940 5000 100
S0 S1 E O M CCS YGC YGCT FGC FGCT CGC CGCT GCT
0.00 100.00 0.36 87.63 94.30 81.06 539 14.021 33 3.972 837 0.976 18.968
0.00 100.00 0.60 69.51 94.30 81.06 540 14.029 33 3.972 839 0.978 18.979
0.00 0.00 0.50 99.81 94.27 81.03 548 14.143 34 4.002 840 0.981 19.126
0.00 100.00 0.59 70.47 94.27 81.03 549 14.177 34 4.002 844 0.985 19.164
0.00 100.00 0.57 99.85 94.32 81.09 550 14.204 34 4.002 845 0.990 19.196
0.00 100.00 0.65 77.69 94.32 81.09 559 14.469 36 4.198 847 0.993 19.659
0.00 100.00 0.65 77.69 94.32 81.09 559 14.469 36 4.198 847 0.993 19.659
0.00 100.00 0.70 35.54 94.32 81.09 567 14.763 37 4.378 853 1.001 20.142
0.00 100.00 0.70 41.22 94.32 81.09 567 14.763 37 4.378 853 1.001 20.142
0.00 100.00 1.89 96.76 94.32 81.09 574 14.943 38 4.487 859 1.007 20.438
0.00 100.00 1.39 39.20 94.32 81.09 575 14.946 38 4.487 861 1.010 20.442
- S0/S1:Survivor区使用率(0~100%)
- E:Eden区使用率
- O:老年代使用率
- M:元空间使用率
- YGC/YGCT:Young GC次数/耗时
- FGC/FGCT:Full GC次数/耗时
jmap
jmap 命令可以生成堆转储快照,常用于分析JVM的垃圾收集器行为、排查堆内存溢出等问题。
生成堆转储文件的命令:
jmap -dump:format=b,file=heap_dump.hprof <PID>
分析堆转储:
- 使用 MAT 打开
heap_dump.hprof。 - 查找
Histogram中对象数量异常的类。
Jconsole
JConsole 是一个基于JMX的GUI工具,用于连接正在运行的JVM,提供强大的可视化界面,允许实时查看堆内存、线程、类加载、MBean等。
查看堆内存使用情况
查看线程情况

查看MBean
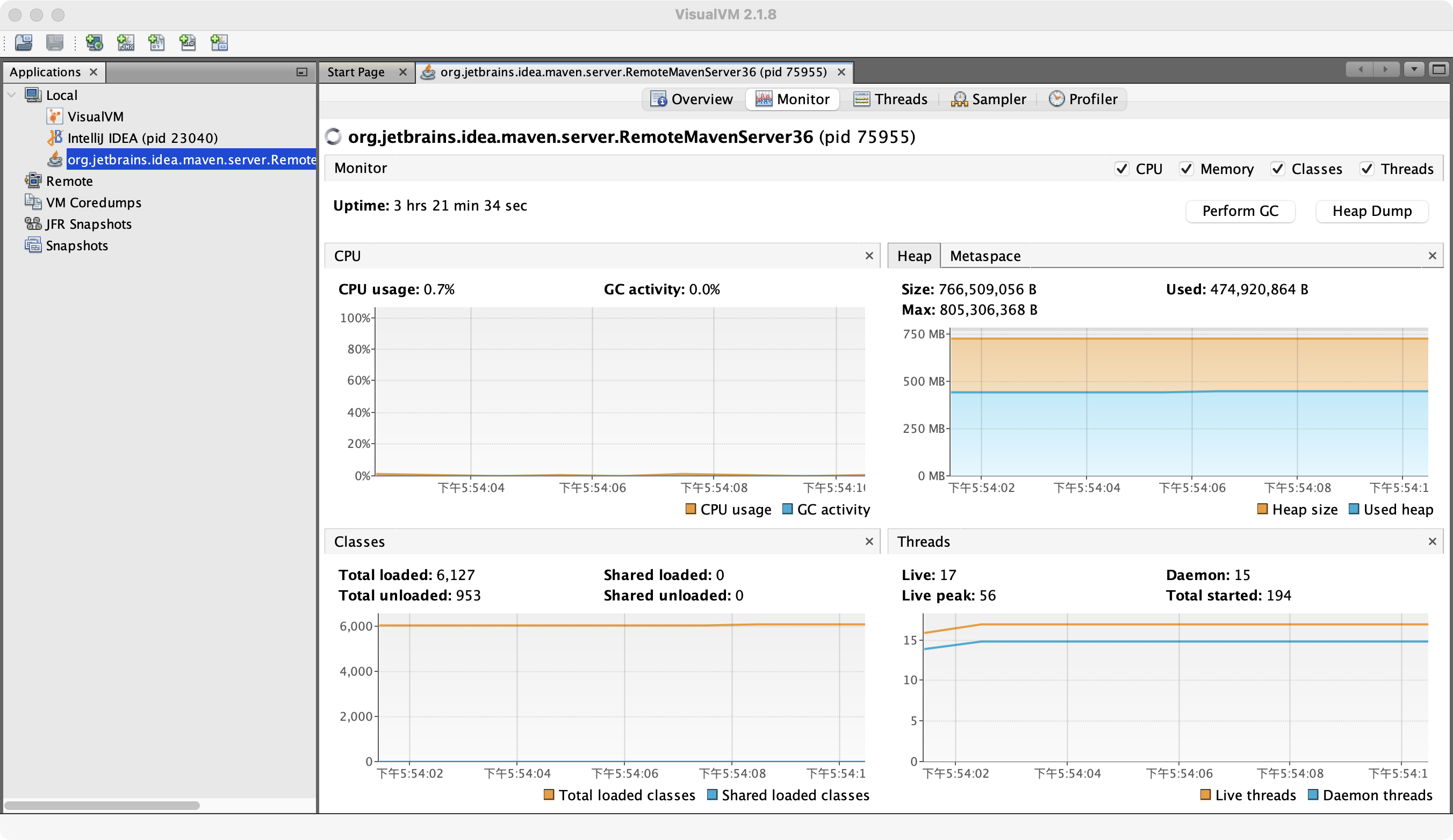
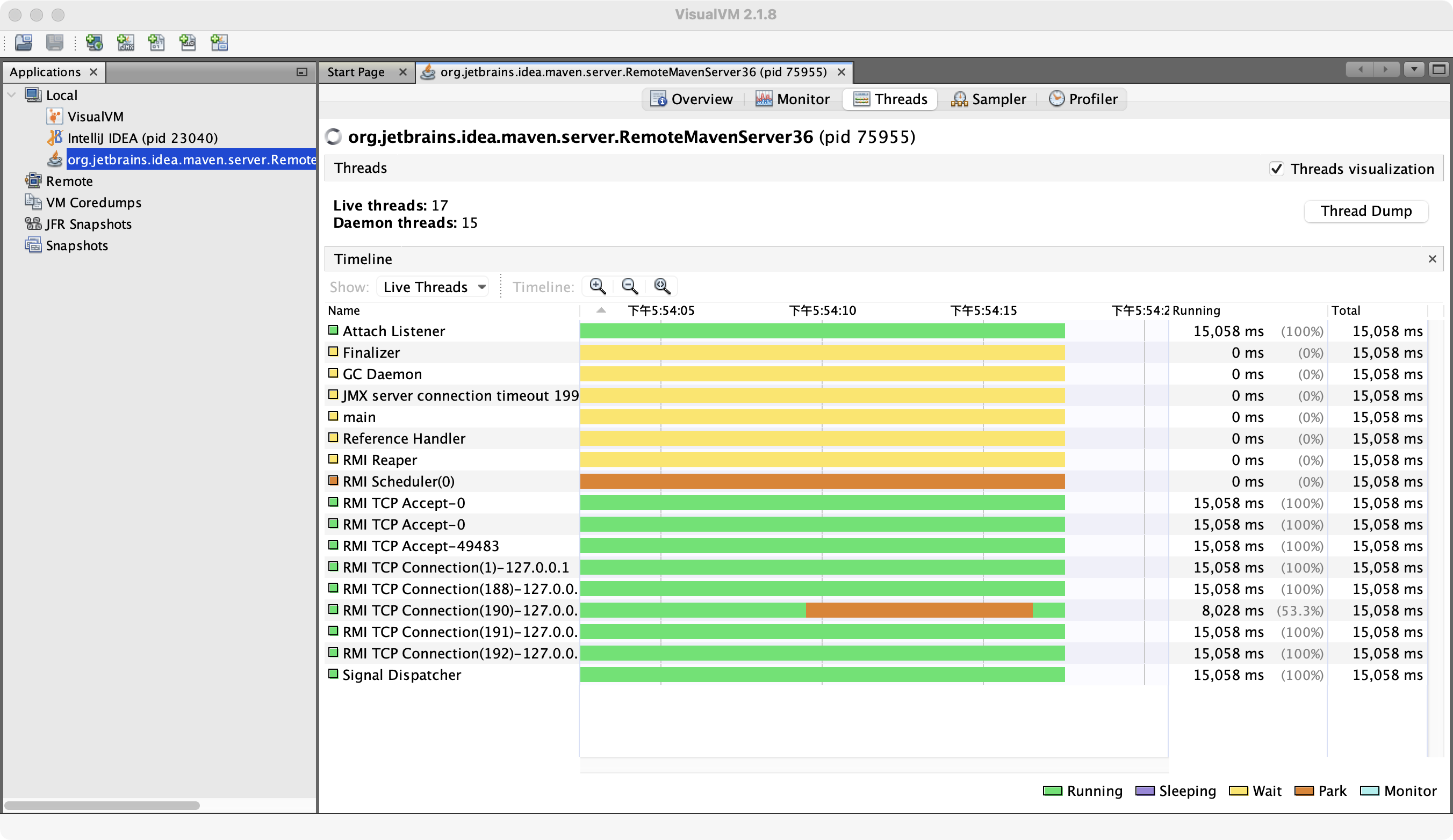
VisualVM
VisualVM 是一个集成多个JDK命令行工具的可视化工具,可以作为Java应用程序性能分析和运行监控的工具。开发人员可以利用它来监控、分析线程信息,浏览内存堆数据。
查看堆内存使用情况
查看线程情况
工具对比与选型建议
| 工具 | 核心功能 | 适用场景 | 操作系统 |
|---|---|---|---|
jstack |
线程快照、死锁检测 | 线程阻塞、死锁排查 | Windows/Linux |
jstat |
GC统计、内存分区监控 | GC调优、内存泄漏初筛 | Windows/Linux |
jmap |
堆转储生成 | OOM问题分析 | Windows/Linux |
JConsole |
图形化综合监控 | 实时运行时状态监控 | Windows/Linux |
VisualVM |
图形化综合监控 | 实时运行时状态监控 | Windows/Linux |
性能剖析工具
JProfiler
在项目启动时选择 Profile xxx with "IntelliJ Profiler’,或者在项目启动后,选择 Profile the Process

Arthas
在idea中,可以安装arthas idea插件,便捷生成 arthas 命令。
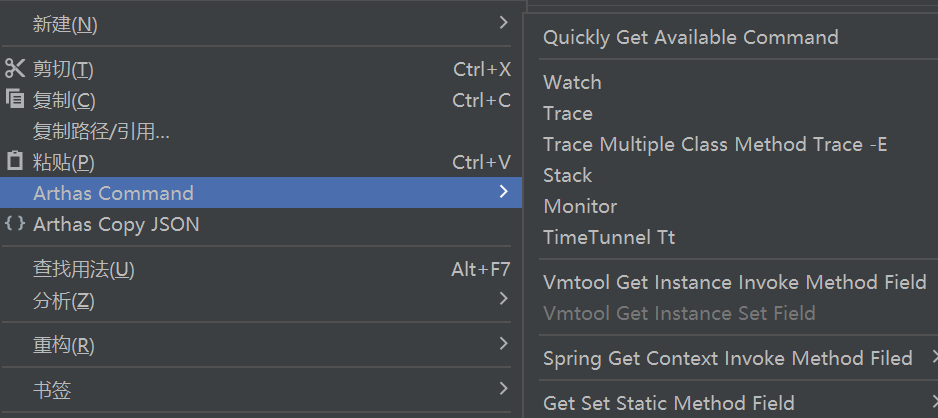
此外,信创环境大多是JRE环境,而官方的arthas需要JDK环境才能运行。koca 提供了no JDK场景下的arthas工具,可以联系koca的同事获取。
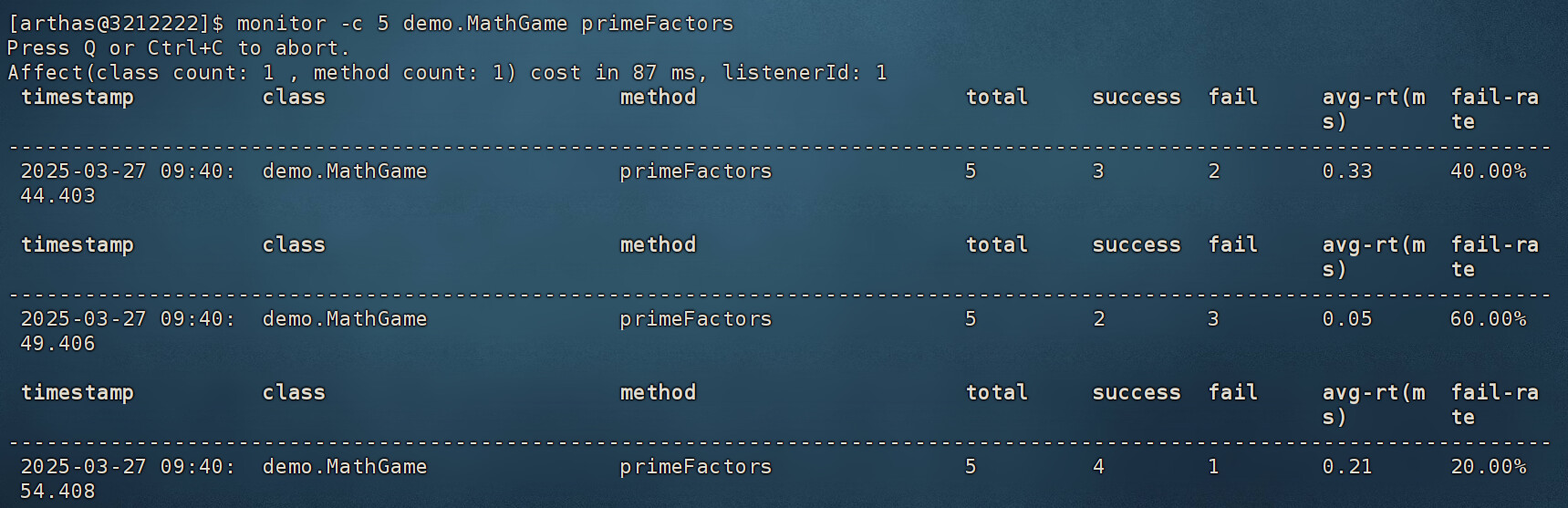
monitor命令
用来监视一个时间段中指定方法的执行情况,包括耗时、成功次数、失败次数等信息。
monitor -c 5 全类名 方法名 # 每过5秒输出一次
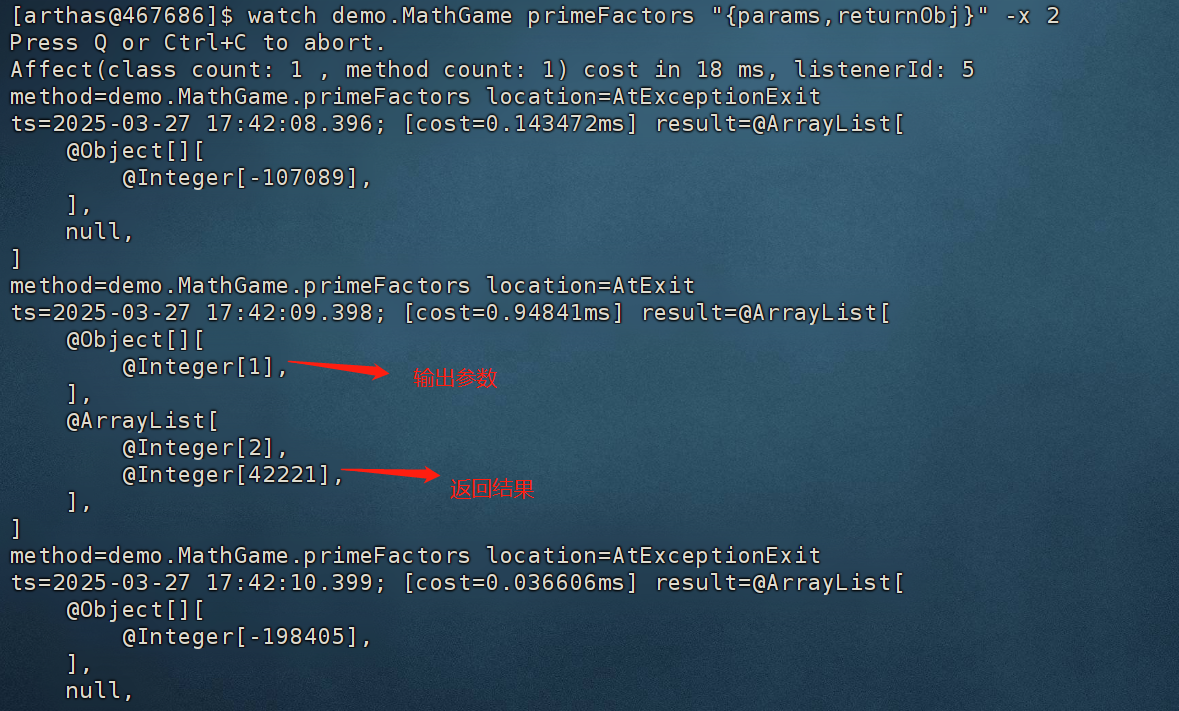
watch命令
用于观察指定方法的入参和出参。
watch 全类名 方法名 "{params,returnObj}" -x 2 # 属性遍历深度为2
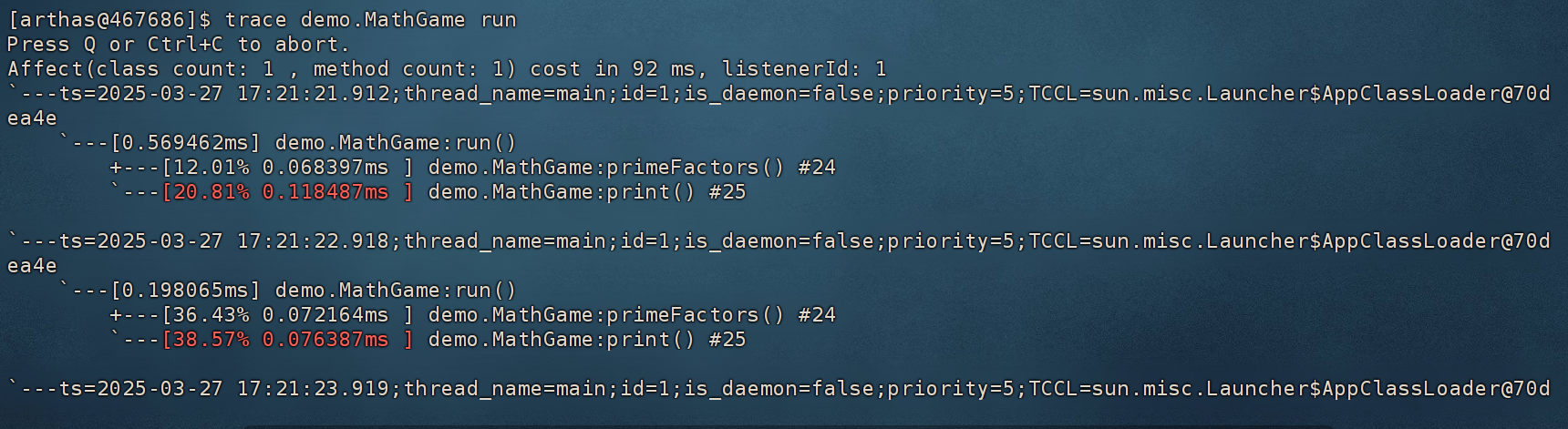
trace命令
对方法内部调用路径进行追踪,并输出方法路径上的每个节点上耗时。
trace函数指定类的指定方法
trace demo.MathGame run
三、常见性能问题排查方法
应用程序响应时间过长
查看方法调用耗时
JProfiler热点图(开发环境)
火焰图上的数据本质上是所有采样堆栈的汇总。分析器收集的具有相同堆栈的样本越多,该堆栈在火焰图上增长得越宽,说明耗时占比越大。至于颜色:堆栈的黄色部分是 Java 代码,蓝色是本机方法调用。
JProfiler 具体使用方法:
在分析器可以看到火焰图,搜索 koca-mybatis 包 com.szkingdom.koca.support.mybatis.interceptor,能看到该方法的耗时占比情况。从图中可以发现 SqlParserInterceptor 类中时间占比比较长。

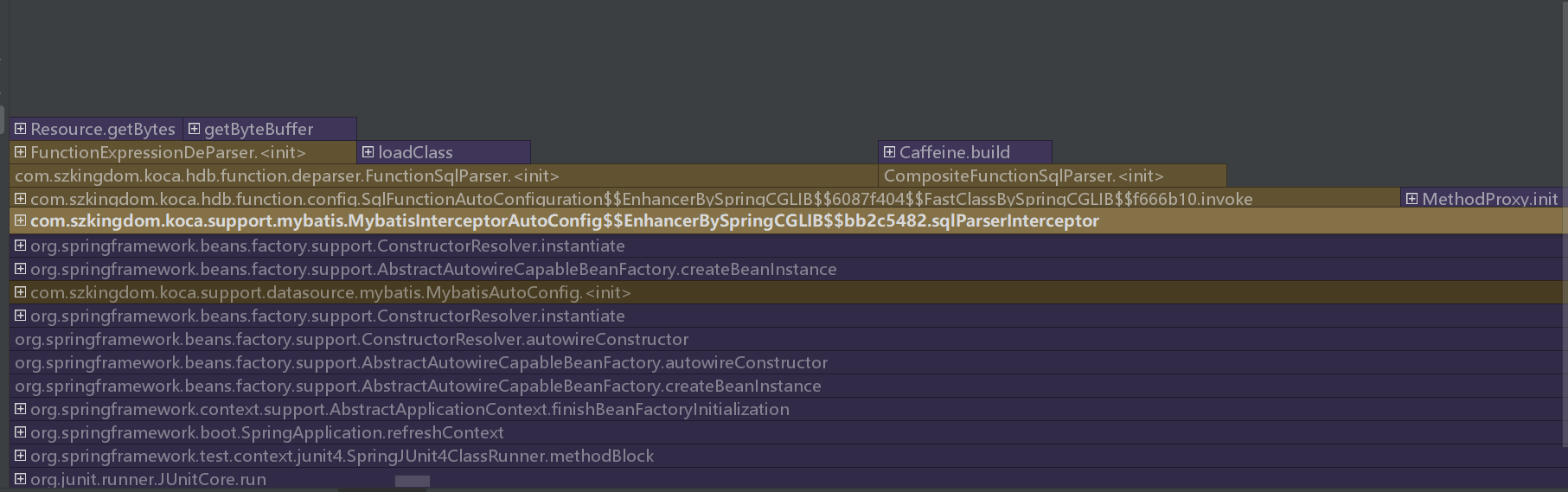
Arthas热点图
可以使用Arthas的profiler start命令开始记录热点图,使用profiler stop命令停止记录热点图。
在生成的图中发现 realTarget 方法耗时占比比较高,进一步排查原因是mybatis的反射去获取真实的StatementHandler耗时过长。
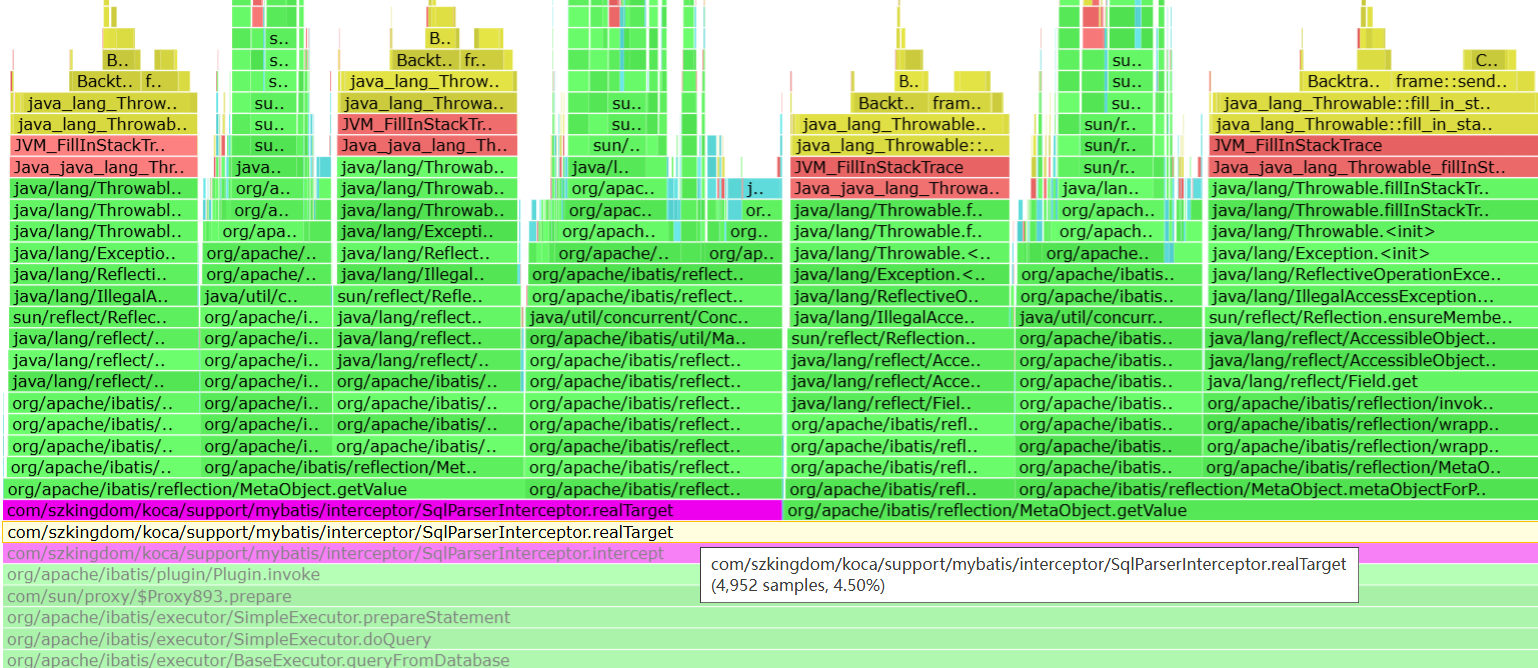
Arthas的trace命令(推荐)
-
trace命令能主动搜索class-pattern/method-pattern对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。具体使用如上:trace命令
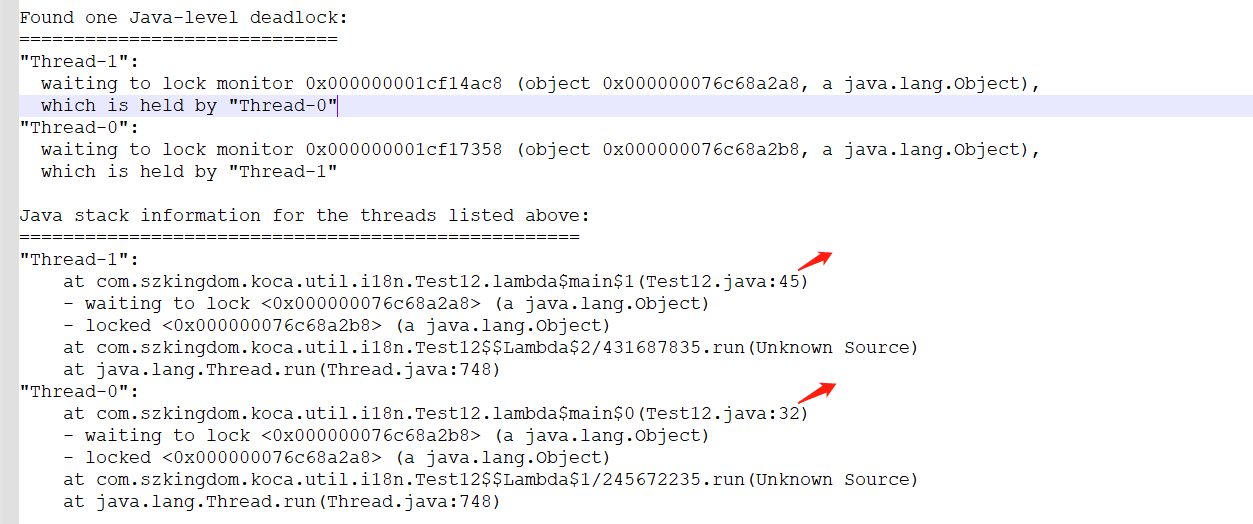
线程死锁问题
使用jstack命令
可以使用jstack排查死锁问题,具体使用请参考:jstack
案例说明
以下案例会出现死锁问题
public class Test12 {
private static Object lockA = new Object();
private static Object lockB = new Object();
public static void main(String[] args) {
new Thread(() ->{
synchronized (lockA) {
try {
System.out.println("线程1开始运行========");
Thread.sleep(2000);
} catch (InterruptedException e) {
}
synchronized (lockB) {
System.out.println("线程1运行结束========");
}
}
}).start();
new Thread(() ->{
synchronized (lockB) {
try {
System.out.println("线程2开始运行========");
Thread.sleep(2000);
} catch (InterruptedException e) {
}
synchronized (lockA) {
System.out.println("线程2结束运行========");
}
}
}).start();
System.out.println("主线程运行结束========");
}
}
排查方法
使用 jps -l 查看进程情况
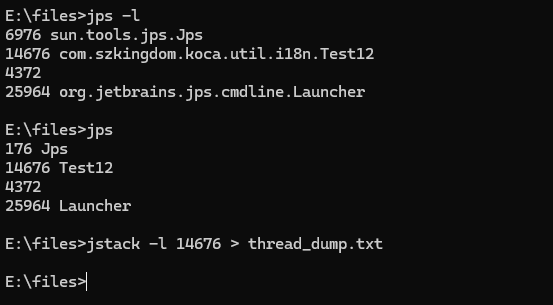
根据打印的代码行号找到指定的代码进一步分析其原因