
分布式缓存中间件解决方案调研
目前KOCA框架使用redis作为分布式缓存中间件,但是redis服务作为native方案不能跟随koca服务同步启动,需要单独部署,同时redis集群配置复杂,所以现在需要寻找一种内嵌在koca服务中可以和koca同步启动的分布式缓存方案
`
Hazelcast 的优势
缓存
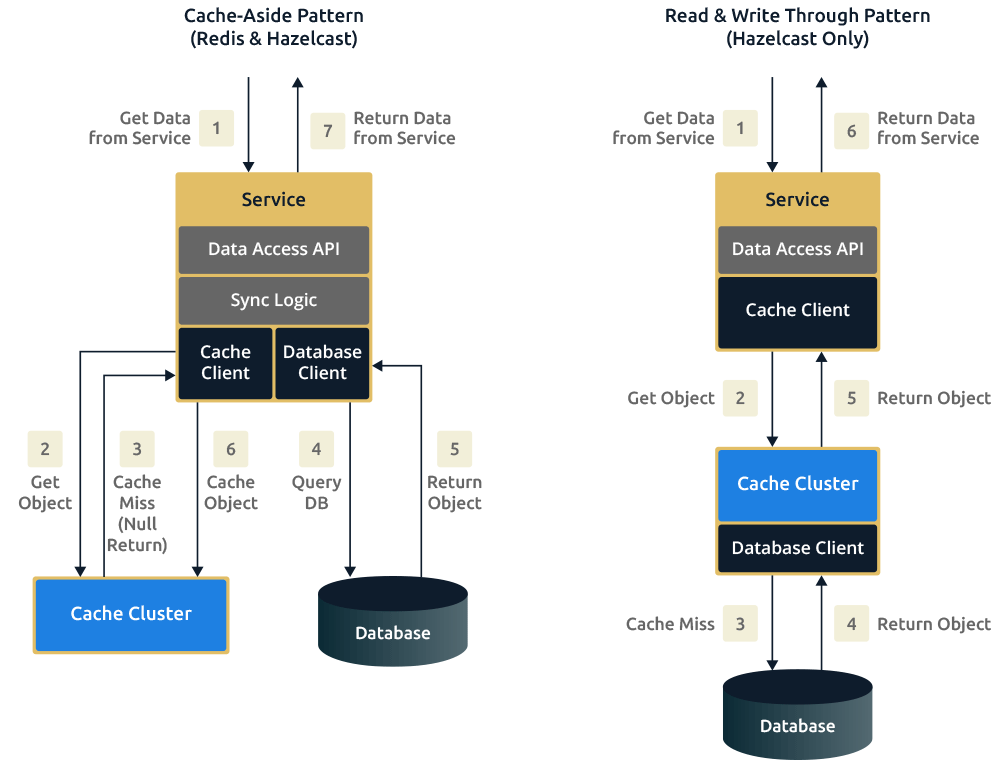
hazelcast open sources版本内置了Read&Write Through、Write Back缓存策略,
Redis需要通过RedisGears框架或Redission来使用这些策略
Near Cache
在分布式架构中,远程操作明显比本地操作要代价更大,near-cache是用来提高Hazelcast集群本地操作占比的功能,开启near-cache后当从远程缓存节点获取到一个对象后会将他放到本地缓存中,随后的请求都会被本地节点处理从本地缓存取得,但是会造成本地内存占用增大同时也会在设定的缓存到期前造成一致性问题。
这项功能在redis中通过redission客户端来提供,jedis没有对应功能
redis和hazelcast的性能对比
benchmark,详细解释性能测试
兼容
可以嵌入java程序中,不需要部署中间件
集群
在集群部署上Hazelcast比redis更加简单
Hazelcast集群部署有三种方法, todo raft协议相关
- 通过eureka、zookeeper等注册中心来自动发现(官方手册里不建议生产环境使用这个方法)
- 通过多播来发现自动发现节点
- 手动配置节点
查询
| Hazelcast | redis | |
|---|---|---|
| String | Map |  |
| List | |
|
| Set | |
|
| Map | |
Redission |
| MultiMap | |
Redission |
| Queue | |
Redission |
| ring buffer | |
|
| Distrubuted Lock | |
Redission |
| AtomicLong | |
|
| Semaphore | |
Redission |
| AtomicReference | |
Redission |
Hazelcast支持集群分片的数据结构:
- Map
- MultiMap
- Cache (Hazelcast JCache implementation)
- Event Journal
Hazelcast不支持集群分片的数据结构:
-
Queue
-
Set
-
List
-
Ringbuffer
-
FencedLock
-
ISemaphore
-
IAtomicLong
-
IAtomicReference
-
FlakeIdGenerator
-
ICountdownLatch
-
Cardinality Estimator
-
PN Counter
hazelcast支持复杂查询, 类SQL查询
文字描述支持的复杂查询
Hazelcast的劣势
hazelcast由于java实现导致的gc开销,开源版和企业版比起来由于没有高密度存储相关功能,所以gc开销会更大
Hazelcast简易使用教程
- 配置文件hazelcast.yml:
hazelcast:
cluster-name: prod #集群名字,
network:
join: # hazelcast提供多种分布式集群组建的方式,下面主要介绍两种
multicast: # 广播模式,使用该模式节点启动时会向同一个网络下其他节点广播来自动加入集群
enabled: false
multicast-group: 224.2.2.3 # 当在同一网络下需要组建多个不同的集群时配置该项来区分
multicast-port: 54327
tcp-ip: # tcp-ip模式, 在启动时向配置的member发送请求来加入请求,member-list中只需要写明集群中的个别节点即可,在所有集群节点的配置中要保证member-list相交, 具体规则参考hazelcast官网
enabled: false
interface: 127.0.0.1
required-member: 10.0.0.1
member-list:
- 10.0.0.2
- 10.0.0.3
- 使用HazelcastInstance:
下面的方法都可以获得一个HazelcastInstance对象
Hazelcast.newHazelcastInstance(); // 创建新的HazelcastInstance (使用hazelcast.yaml作为配置)
Hazelcast.getOrCreateHazelcastInstance() // 获取或创建一个HazelcastInstance (使用hazelcast.yaml作为配置)
Hazelcast.getOrCreateHazelcastInstance(Config config) // 获取或创建一个HazelcastInstance (使用参数作为配置)
Hazelcast.getHazelcastInstanceByName(); // 通过名字获取已经创建的 HazelcastClient.newHazelcastClient(); // 创建一个客户端Instance
HazelcastInstance.getXXX方法来获取和创建对应的数据结构
hazelcastInstance.getMap("A") //获取一个实现了java.util.Map接口的IMap对象, 对象名为“A”
hazelcastInstance.getSet("A") //获取一个实现了java.util.Set接口的ISet对象, 对象名为“A”
// 以此类推上面的数据类型都可以通过这种方式获得
总结
Hazelcast目前在功能上和Redis差别有限,,但是在很多redis需要额外插件来扩展的内容整合到了内部,可以内置在Java应用程序中启动, 同时在使用上更加直观,缺点则是目前hazelcast使用人群比起redis还是非常小众,在现阶段作为一个Redis的可选替换项集成在koca-cache中